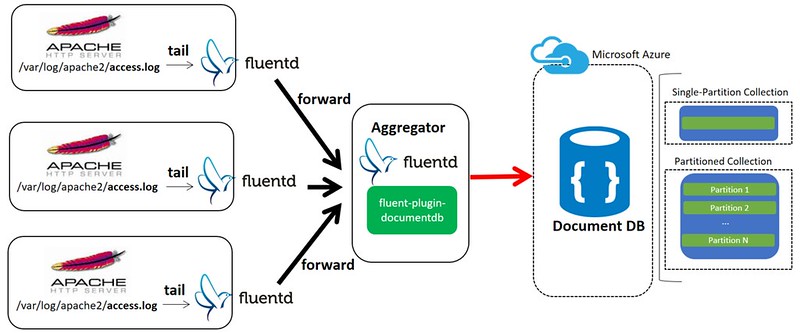
I’d like to announce fluent-plugin-documentdb finally supports Azure DocumentDB Partitioned collections for higher storage and throughput. If you’re not familiar with fluent-plugin-documentdb, read my previous article before move on.
Partitioned collections is kick-ass feature that I had wanted to support in fluent-plugin-documentdb since the feature came out public (see the announcement). For big fan of fluent-plugin-documentdb, sorry for keeping you waiting for such a long time :-) If I may make excuses, I would say I haven’t had as much time on the project, and I had to do ruby client implementation of Partitioned collections by myself as there is no official DocumentDB Ruby SDK that supports it (As a result I’ve created tiny Ruby DocumentDB client libraries that support the feature. Check this out if you’re interested).
What are Partitioned collections?
According to official documentation, Partitioned collections can span multiple partitions and support very large amounts of storage and throughput. You must specify a partition key for the collection. Partitioned collections can support larger data volumes and process more requests compared to Single-partitioned collection. Partitioned collections support up to 250 GB of storage and 250,000 request units per second of provisioned throughput[Updated Aug 21, 2016] (@arkramac pointed that out for me) Partitioned collections support unlimited storage and throughput. 250GB storage and 250k req/sec are soft cap. You can increase these limits by contacting and asking Azure support.
On the other hand, Single-partition collections have lower price options and the ability to query and perform transactions across all collection data. They have the scalability and storage limits of a single partition. You do not have to specify a partition key for these collections.
Creation of Partitioned collections
You can create Partitioned collections via the Azure portal, REST API ( >= version 2015-12-16), and client SDKs in .NET, Node.js, Java, and Python. In addition, you let fluent-plugin-documentdb create Partitioned collections automatically by adding the following configuration options upon the ones for single-partitioned collection in fluentd.conf:
- auto_create_collection true
- partitioned_collection true
- partition_key [partition key for the collection]
- offer_throughput [Offer throughtput value: must be more than and equals to
10100. See this for more info on offer throughtput in creating collection]
It creates a partitioned collection as you configure in starting the plugin if not exist at that time.
Configuration Example
Suppose that you want to read Apache access log as source for fluentd, and that you pick “host” as a partition Key for the collection, you can configure the plugin like this following:
<source>
@type tail # input plugin
path /var/log/apache2/access.log # monitoring file
pos_file /tmp/fluentd_pos_file # position file
format apache # format
tag documentdb.access # tag
</source>
<match documentdb.*>
@type documentdb
docdb_endpoint https://yoichikademo.documents.azure.com:443/
docdb_account_key Tl1xykQxnExUisJ+BXwbbaC8NtUqYVE9kUDXCNust5aYBduhui29Xtxz3DLP88PayjtgtnARc1PW+2wlA6jCJw==
docdb_database mydb
docdb_collection my-partitioned-collection
auto_create_database true
auto_create_collection true
partitioned_collection true
partition_key host
offer_throughput 10100
localtime true
time_format %Y%m%d-%H:%M:%S
add_time_field true
time_field_name time
add_tag_field true
tag_field_name tag
</match>
Basically that’s all additional configuration for Partitioned collections. Please refer to my previous article for the rest of setup and running work for the plugin.
Happy log collections with fluent-plugin-documentdb!!