これはElasticsearch Advent Calendar 2015の17日目のエントリー
ARMテンプレートと呼ばれるデプロイ手法を使ってAzure上にElasticsearchクラスタをさくっと構築する方法についてのお話で、主にAzure界隈のElasticsearchユーザ向けの内容となっている。タイトルにある3分でというのは実際に計ったわけではないがそれくらい簡単且つ短時間でできることを強調したく使わせていただいている・・・ということを前もって補足しておく(汗)。
ARMテンプレートとは?
ARMテンプレートの前にARMについて少し解説する。ARMはAzure Resource Managerの略で、アプリケーション構築に必要な
リソース(ストレージ、ネットワーク、コンピュート/仮想マシンなど)をデプロイし管理するための仕組みである。どんなソリューションのデプロイにおいても少なからず仮想ネットワーク、仮想マシン、ストレージ、LBなどのインフラの構築が必要で旧来のやり方ではこれらを1つ1つデプロイしていたかと思う。一方ARMの世界では必要な構築要素をリソースという単位にして、これらリソースを個別にデプロイするのではなく全てのリソースをグループ化してまとめてデプロイし、それらを管理・監視することができる。そして、それら複数のリソースはJSON形式のテンプレートで表現・展開できるようになっていて、このテンプレートのことをARMテンプレートと呼ぶ。Infrastructure as Codeなんて言葉がはやっていたりするが、まさにそれをAzureで実現するための公式な仕組みがARMであり、ARMテンプレートなのである。
ちなみにこのARMテンプレート、手でいちから作る必要はなく、Azureクイックスタートテンプレートにさまざまなテンプレートが公開されているのでまずは自分の目的に似たようなことを実現しているテンプレートを選んでデプロイしてみることをお勧めする。完成されたものを見ることでお作法が学べるし、それをベースにカスタマイズしていくのが効率的である。
- https://azure.microsoft.com/ja-jp/documentation/templates/
- https://github.com/Azure/azure-quickstart-templates
Elasticsearchクラスタのデプロイ
上記で説明したARMテンプレートを利用してElasticsearchクラスタのデプロイを行う。ここで使うARMテンプレートはAzureクイック・スタートテンプレートギャラリーにあるElasticsearchテンプレートを利用する。ARMテンプレートを使ったデプロイには複数の方法があるがここではLinux上でAzure CLIを使った方法で行う。ここでの実行OSはUbuntu 14.10。
最新版のAzure CLIをインストールしてからAzureサブスクリプションに接続する
$ sudo npm install -g azure-cli
$ azure --version
$ azure login
「Azure コマンド ライン インターフェイス (Azure CLI) からの Azure サブスクリプションへの接続」に書かれているように、Azure CLI バージョン 0.9.10 以降では、対話型の azure login コマンドを使用して、任意の ID でアカウントにログインできる。尚、バージョン 0.9.9 以降は、多要素認証をサポートしている。
デプロイ用のリソースグループを作成する
ここでは西日本(Japan West)リージョンにResource-ES-JapanWestという名前のリソースグループを作成する。
# azure group create -n "<リソースグループ名>" -l "<リージョン名>"
$ azure group create -n "Resource-ES-JapanWest" -l "Japan West"
ARMテンプレートのダウンロードとパラメータの編集
Githubよりazure-quickstart-templatesをコピーして、Elasticsearch用テンプレートディレクトリに移動する
$ git clone https://github.com/Azure/azure-quickstart-templates.git
$ cd azure-quickstart-template/elasticsearch
azuredeploy.parameters.jsonを編集してデプロイ用パラメータを入力する。ここでの入力内容は下記のとおり
{
"$schema": "http://schema.management.azure.com/schemas/2015-01-01/deploymentParameters.json#",
"contentVersion": "1.0.0.0",
"parameters": {
"adminUsername": {
"value": "yoichika" # 管理用ユーザ名
},
"adminPassword": {
"value": "*********" # 上記管理ユーザパスワード
},
"vmDataNodeCount": {
"value": 3 # データノード数
},
"virtualNetworkName": {
"value": "esvnet" # 仮想ネットワーク名
},
"esClusterName": {
"value": "elasticsearch" # ESクラスタ名
},
"loadBalancerType": {
"value": "internal" # LBタイプ external or internal
},
"vmSizeDataNodes": {
"value": "Standard_D1" # データノード用のVMインスタンスサイズ
},
"vmClientNodeCount": {
"value": 0 #クライアントノード数
},
"marvel": {
"value": "no" # Marvel有効化: yes or no
},
"kibana": {
"value": "yes" # Kibana有効化: yes or no
},
"OS": {
"value": "ubuntu"
}
}
}
ARMテンプレートを元にクラスタのデプロイ
一通り準備が整ったのでARMテンプレートを元に上記で作成したリソースグループにESクラスタをデプロイする。
# azure group create "<resource group名>" "<リージョン>" \
# -f <azuredeploy.jsonファイル>
# -d "<deploy名>"
# -e <azuredeploy.parameters.jsonファイル>
$ azure group create "Resource-ES-JapanWest" "JapanWest" \
-f azuredeploy.json \
-d "Deploy-ES-JapanWest" \
-e azuredeploy.parameters.json
途中のデプロイメント状況は次のコマンドで確認することができる。
# azure group deployment show "<Resource group名>" "<deployment名>"
$ azure group deployment show "Resource-ES-JapanWest" "Deploy-ES-JapanWest"
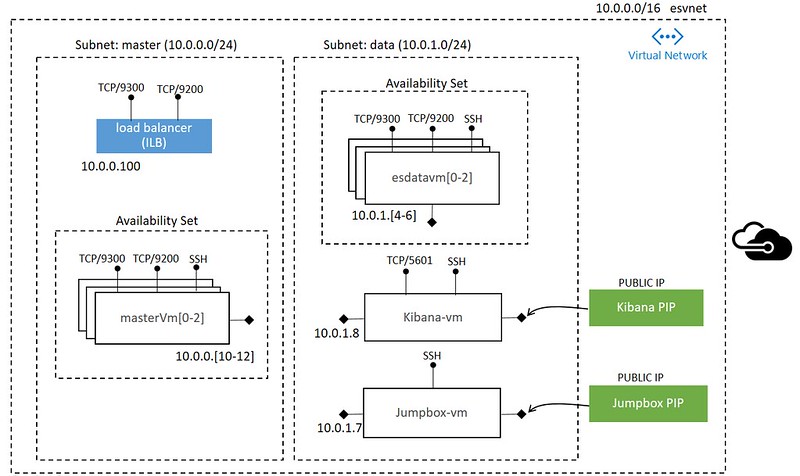
上記コマンドの処理が完了すればデプロイ完了。たったこれだけ。出来上がった構成だが、手っ取り早くはAzureポータルで確認することができる。デプロイ用に作成したリソースグループ(ここではResource-ES-JapanWest)の中身を見ていただくとデプロイされた様々なリソース一覧(ストレージ、仮想ネットワーク、ロードバランサー、仮想マシン、ネットワークセキュリティグループ、パブリック用IP・・・など)が出来上がっていることが分かる。尚、出来上がったESクラスタは合計8VMで構成されており、ESマスターノード用に3つ、ESデータノード用に3つ、Kibana用に1つ、踏み台サーバ用に1つとなっている。仮想ネットワーク内のVMの配置状況を図にすると次のようになる。
テスト実行
テスト用のデータセットを投入して、問題なくクラスタが動作するのかを確認してみる。データはこちらでテストに提供されている shakespeare.jsonを利用する。shakespeare.jsonをダウンロード済みであること前提に下記のようにESクラスタにデータを投入する。
まずはshakespeareデータセットのためにフィールドのMappingを実行
curl -XPUT http://<ESノードのアドレス>:9200/shakespeare -d '
{
"mappings" : {
"_default_" : {
"properties" : {
"speaker" : {"type": "string", "index" : "not_analyzed" },
"play_name" : {"type": "string", "index" : "not_analyzed" },
"line_id" : { "type" : "integer" },
"speech_number" : { "type" : "integer" }
}
}
}
}
';
次にshakespeareデータセットをESクラスタにロード。
$ curl -XPOST "<ESノードのアドレス>:9200/shakespeare/_bulk?pretty" --data-binary @shakespeare.json
上記処理完了後無事ロードが完了したかどうかインデックスのステータスを確認する。
$ curl '<ESノードのアドレス>:9200/_cat/indices?v'
(結果)
health status index pri rep docs.count docs.deleted store.size pri.store.size
green open shakespeare 5 1 111396 0 36.2mb 18mb
green open .kibana 1 1 2 0 35.6kb 17.8kb
念のために検索クエリーを投げてみる。
$ curl -s '<ESノードのアドレス>:9200/shakespeare/_search?q=*&size=1' | \
python -mjson.tool| perl -Xpne 's/\\u([0-9a-fA-F]{4})/chr(hex($1))/eg'
(結果)
{
"_shards": {
"failed": 0,
"successful": 5,
"total": 5
},
"hits": {
"hits": [
{
"_id": "4904",
"_index": "shakespeare",
"_score": 1.0,
"_source": {
"line_id": 4905,
"line_number": "3.3.74",
"play_name": "Henry VI Part 1",
"speaker": "JOAN LA PUCELLE",
"speech_number": 18,
"text_entry": "See, then, thou fightst against thy countrymen"
},
"_type": "line"
}
],
"max_score": 1.0,
"total": 111396
},
"timed_out": false,
"took": 9
}
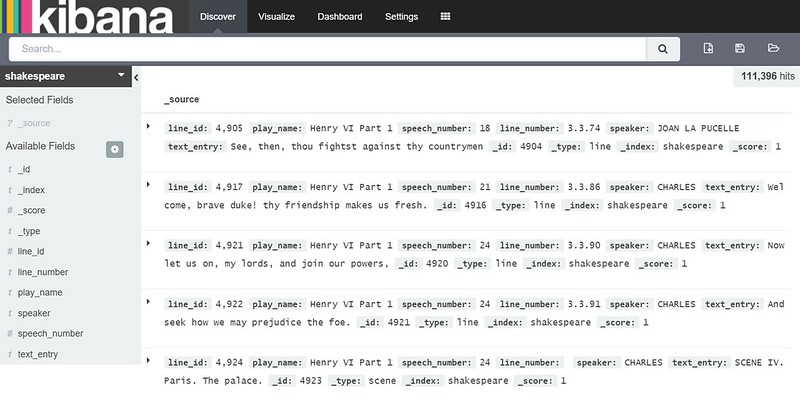
さらにKibanaにアクセスしてESクラスタとの連携に問題がないか確認する。念のためにKibanaのエントリポイントはhttp://Kibanaアドレス:5601。特に問題なければKibana上で検索すると次のようにテストロードしたデータセットが閲覧できるはず。
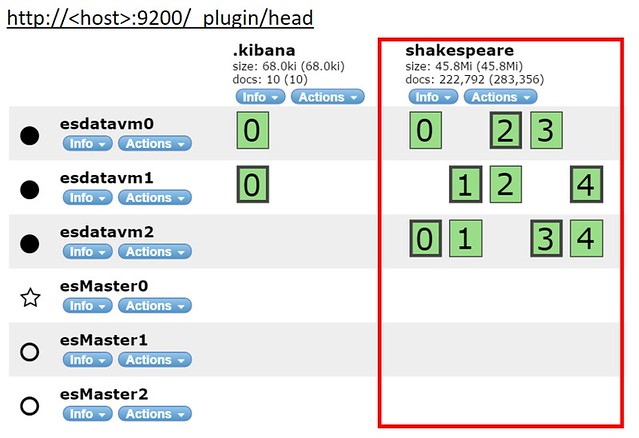
elasticsearch-headでクラスタノードの状態を確認
elasticsearch-headはクラスタの構成やインデックスの中身表示、検索クエリの作成、結果取得など手軽に確認することができる便利なGUIツール。このelasticsearch-headを使ってクラスタノードの状態を確認する。インストールは次のようにプラグインコマンドで行う。
$ sudo /usr/share/elasticsearch/bin/plugin install mobz/elasticsearch-head
elasticsearch-headのエントリーポイントはhttp://:9200/_plugin/headで結果は次のとおり。
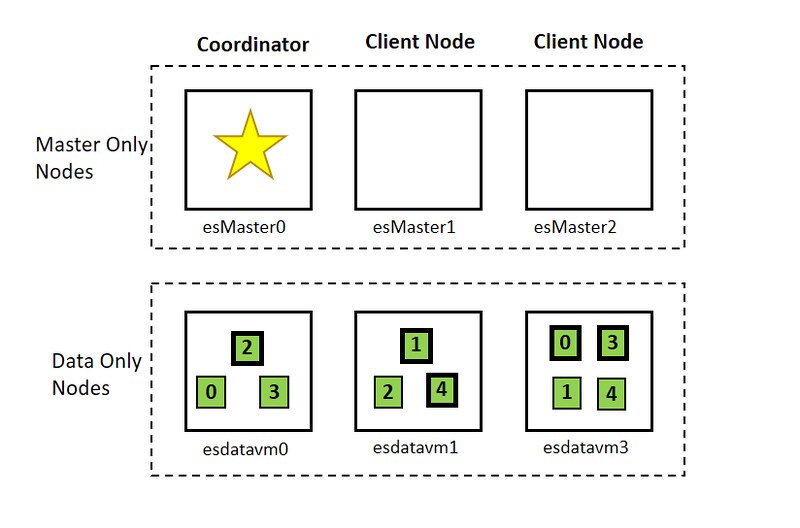
これを分かりやすくトポロジーにしてみたのが下図。緑の太枠のところがプライマリーシャードで細枠がレプリカシャードを表す。
ノードdiscoveryについて
Elasticsearchはノードdiscovery方式としてデフォルトでmulticastモードを使うようになっており、ノード間でクラスタ名(ここではelasticsearch)を合わせることで内部的に勝手にクラスタ構成を組んでくれるようになっている。このクラスタ内ノード探索はzen discoveryという探索モジュールが使われている。ただし、Azureの場合は仕組み上マルチキャストが利用できない(これはAWSでも同じ)ためunicastモードを使って見つける必要がある。
ノードdiscovery方式はelasticsearchの設定ファイルelasticsearch.ymlに指定し、unicastモードの場合はdiscovery.zen.ping.unicast.hostsパラメターにノード群のIPをカンマ区切りで指定する。参考までに今回のデータノードのelasticsearch.ymlでは下記のように3つのデータノードのIPをdiscovery.zen.ping.unicast.hostsに指定している。
/etc/elasticsearch/elasticsearch.yml
cluster.name: elasticsearch
node.name: esdatavm0
path.data: /datadisks/disk2/elasticsearch/data,/datadisks/disk1/elasticsearch/data
discovery.zen.ping.multicast.enabled: false
discovery.zen.ping.unicast.hosts: ["10.0.0.10","10.0.0.11","10.0.0.12"]
node.master: false
node.data: true
discovery.zen.minimum_master_nodes: 2
network.host: _non_loopback_
Azure Cloud pluginの紹介
最後にAzure Cloud pluginの紹介をしたい。これはAzure APIを使って自動でAzureに展開されたノードの探索を行うことができるノードdiscoveryプラグインで、unicastモードのようにノードIPをいちいち指定する必要がない点でmulticastモードに似ている。ただし注意点としてこのプラグインはクラシックデプロイモデル管理下のリソース(V1)のみとなっている。よって、今回のようにARMテンプレートでデプロイしたESクラスタは対象外であるが、もしクラシックモデルでデプロイしたESクラスタであればノードdiscovery方式の1つとして是非お試しいただければと思う。
Enjoy Elasticsearch on Azure!!
おわり