DocumentDB Python SDKとfeedparserを使って簡易クローラーを作りましょうというお話。ここではDocumentDBをクローリング結果の格納先データストアとして使用する。クロール対象はAzure日本語ブログのRSSフィード、これをfeedparserを使ってドキュメント解析、必要データの抽出、そしてその結果を今回使用するpydocumentdbというDocumentDB Python SDKを使ってDocumentDBに格納するというワークフローになっている。
DocumentDB Python SDK - pydocumentdb
Azureで提供されているどのサービスにもあてはまることであるが、DocumentDBを操作するための全てのインターフェースはREST APIとして提供されておりREST APIを内部的に使用してマイクロソフト謹製もしくは個人のコントリビューションによる複数の言語のSDKが用意されている。その中でもpydocumentdbはPython用のDocumentDB SDKであり、オープンソースとしてソースコードは全てGithubで公開されている。
Pre-Requirementsその1: Python実行環境とライブラリ
実行環境としてPython2.7系が必要となる。また、今回クローラーが使用しているDocumentDB Python SDKであるpydocumentdbとRSSフィード解析ライブラリfeedparserの2つのライブラリのインストールが必要となる。
pydocumentdbインストール
$ sudo pip install pydocumentdb
feedparserインストール
$ sudo pip install feedparser
ちなみにpipがインストールされていない場合は下記の通りマニュアルもしくはインストーラーを使用してpipをインストールが必要となる
pip マニュアルインストール
# download get-pip.py
$ wget https://bootstrap.pypa.io/get-pip.py
# run the following (which may require administrator access)
$ sudo python get-pip.py
# upgrade pip
$ sudo pip install -U pip
インストーラーを使用
# apt-getの場合
$ sudo apt-get install python-pip
# yumの場合
$ sudo yum install python-pip
Pre-requirementsその2: DocumentDBアカウント
Azure新ポータルより下記イメージのフローでDocumentDBアカウントを作成する。
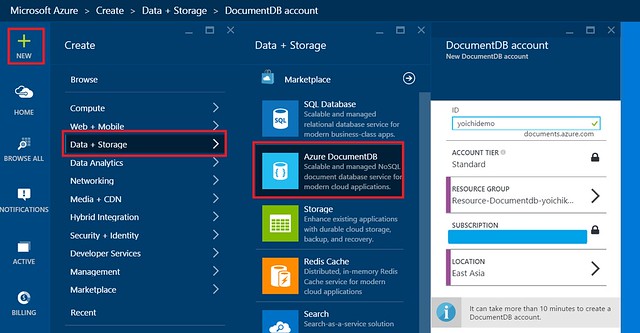
DocumentDBアカウントを作成したら今度はデータを格納するためのDocumentDBデータベースとコレクションを作成する必要がある。DocumentDBデータベースとコレクションはAzure新ポータルから作成可能であるが、今回のクローラープログラムではpydocumentdbを使って作成するようにしている。
RSSクローラーとその実行結果
RSSクローラーのソースコード(rssCrawler4Docdb.py)とその実行結果は下記の通り。もしクローリングを定期的に実行する場合はこのスクリプトをジョブスケジューラー(cronなど)に登録ください。指定のRSSフィードに新しく追加された記事のみがDocumentDBに反映されるようスクリプト上は重複チェックを入れている。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import feedparser
import pydocumentdb.documents as documents
import pydocumentdb.document_client as document_client
import pydocumentdb.errors as errors
import pydocumentdb.http_constants as http_constants
Docdb_masterKey = '<Your Documentdb master key string>'
Docdb_host = 'https://<documentdb account>.documents.azure.com:443/'
Docdb_dbname = '<documentdb database name>'
Docdb_colname = '<documentdb collection name>'
feedurl='http://blogs.msdn.com/b/windowsazurej/atom.aspx'
def rsscrawling():
# create documentDb client instance
client = document_client.DocumentClient(Docdb_host,
{'masterKey': Docdb_masterKey})
# create a database if not yet created
database_definition = {'id': Docdb_dbname }
databases = list(client.QueryDatabases({
'query': 'SELECT * FROM root r WHERE r.id=@id',
'parameters': [
{ 'name':'@id', 'value': database_definition['id'] }
]
}))
if ( len(databases) > 0 ):
feeddb = databases[0]
else:
print "database is created:%s" % Docdb_dbname
feeddb = client.CreateDatabase(database_definition)
# create a collection if not yet created
collection_definition = { 'id': Docdb_colname }
collections = list(client.QueryCollections(
feeddb['_self'],
{
'query': 'SELECT * FROM root r WHERE r.id=@id',
'parameters': [
{ 'name':'@id', 'value': collection_definition['id'] }
]
}))
if ( len(collections) > 0 ):
collection = collections[0]
else:
print "collection is created:%s" % Docdb_colname
collection = client.CreateCollection(
feeddb['_self'], collection_definition)
# request & parse rss feed via feedparser
feed=feedparser.parse(feedurl)
for entry in feed[ 'entries' ]:
document_definition = { 'title':entry[ 'title'],
'content':entry['description'],
'permalink':entry[ 'link' ],
'postdate':entry['date'] }
# check if duplicated
documents = list(client.QueryDocuments(
collection['_self'],
{
'query': 'SELECT * FROM root r WHERE r.permalink=@permalink',
'parameters': [
{ 'name':'@permalink', 'value':document_definition['permalink'] }
]
}))
if (len(documents) < 1):
# only create if it's fully new document
print "document is added:title:%s" % entry['title']
created_document = client.CreateDocument(
collection['_self'], document_definition)
if __name__ == '__main__':
rsscrawling()
[実行結果]
database is created:feeddb
collection is created:article_collection
document is added:title:業界トップのクラウド アナリストがマイクロソフトに転身した理由
document is added:title:Azure Linux VM のインフラストラクチャの監視と診断
document is added:title:Azure App Service の Web アプリ用 Support Site Extension の追加更新
document is added:title:Azure CDN でカスタムのオリジン サーバーをサポート
document is added:title:Tinfoil Security の Azure App Service 向け Web 脆弱性スキャン機能
document is added:title:Azure Site Extensions の自動更新が可能に
document is added:title:DocumentDB へのデータのインポートがより高速、簡単に
document is added:title:Query Store: データベース版フライト データ レコーダー機能
document is added:title:Azure App Service の Web アプリで使用される TLS の中間証明書
document is added:title:Azure で Cloud Foundry をお試しください
document is added:title:Azure Media Indexer の更新版 v1.2.1 をリリース: 前回からの修正点について
document is added:title:クラウド環境でエンドツーエンドのビデオ ワークフローを構築する
document is added:title:Azure Media Player の更新と UserVoice フォーラムのお知らせ
document is added:title:Microsoft Azure 関連ニュース 2015 年 5 月のまとめ
document is added:title:Azure Media Services 向け Hyperlapse のパブリック プレビューを発表
document is added:title:6 月 1 日以降の Application Insights の料金設定
document is added:title:StorSimple Update 1 を発表: Azure Government で提供開始、他社クラウドと ZRS をサポート、5000/7000 シリーズからの移行に対応
document is added:title:成功から転落の危機に直面した Sleeve Music。経験豊かな開発者と適切なツールの選択で新たなアイデアを創出
document is added:title:Azure Storage に関する Build 2015 での発表
document is added:title:Visual Studio Code と Azure App Service の連携で実現できること
document is added:title:Azure Automation でグラフィック形式とテキスト形式の作成機能を導入
document is added:title:接続性の高い安定したハイブリッド クラウドの実現に向けた新しいネットワーク機能
document is added:title:DocumentDB の新しいインポート オプション
document is added:title:Azure Site Recovery が NetApp Private Storage for Microsoft Azure をサポート
document is added:title:Application Insights で ASP.NET 5 アプリケーションをサポート