In this article, I’d like to introduces a solution to collect logs and store them into Azure DocumentDB using fluentd and its plugin, fluent-plugin-documentdb.
Azure DocumentDB is a managed NoSQL database service provided by Microsoft Azure. It’s schemaless, natively support JSON, very easy-to-use, very fast, highly reliable, and enables rapid deployment, you name it. Fluentd is an open source data collector, which lets you unify the data collection and consumption for a better use and understanding of data. fluent-plugin-documentdb is fluentd output plugin that enables to store event collections into Azure DocumentDB.
This article shows how to
- Collect Apache httpd logs across web servers
- Ship the collected logs into the aggregator Fluentd in near real-time
- Store the collected logs into DocumentDB
- Utilize the collected log data stored on Document DB for advanced scenarios - like archiving the data to Azure Storage, doing Big data analysis, visualizing the data with PowerBI, and so forth
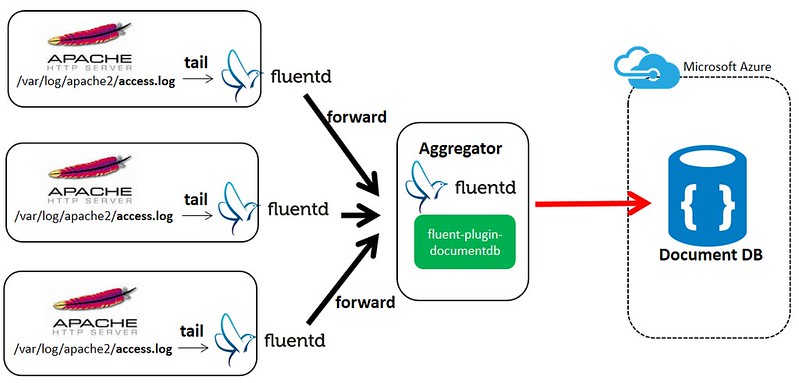
Pre-requisites
- A basic understanding of fluentd - if you’re not familiar with fluentd, fluentd quickstart guide is good starting point
- Azure subscription - you need to have Azure subscription that grants you access to Microsoft Azure services, and under which you can create DocumentDB cluster. If you don’t have yet click here to create it
Setup: Azure DocumentDB
To use Azure DocumentDB, you must create a DocumentDB database account using either the Azure portal, Azure Resource Manager templates, or Azure command-line interface (CLI). In addition, you must have a database and a collection to which fluent-plugin-documentdb writes event-stream out. Here are instructions:
- Create a DocumentDB database account using the Azure portal, or Azure Resource Manager templates and Azure CLI
- How to create a database for DocumentDB
- Create a DocumentDB collection
Setup: Fluentd Aggregator
First of all, install Fluentd. The following shows how to install Fluentd using Ruby gem packger but if you are not using Ruby Gem for the installation, please refer to this installation guide where you can find many other ways to install Fluentd on many platforms.
# install fluentd
$ sudo gem install fluentd --no-ri --no-rdoc
# create fluent.conf
$ fluentd --setup
Also, install fluent-plugin-documentdb for fluentd aggregator to store collected logs data into Azure DocumentDB.
$ sudo gem install fluent-plugin-documentdb
Next, configure fluent.conf, a fluentd configuration file as follows. Please see this for fluent-plugin-documentdb configuration.
# Receive events from 24224/tcp
# This is used by log forwarding and the fluent-cat command
<source>
@type forward
port 24224
</source>
# Store Data in DocumentDB
<match apache.access>
@type documentdb
docdb_endpoint https://yoichikademo.documents.azure.com:443/
docdb_account_key Tl1+ikQtnExxxUisJ+BXwbbaC8NtUqYVE9kUDXCNust5aYBduhui29Xtxz3DLP88PayjtgtnARc1PW+2wlA6jCJw== (dummy)
docdb_database LogDB
docdb_collection Collection1
auto_create_database true
auto_create_collection true
time_format %Y%m%d-%H:%M:%S
localtime true
add_time_field true
time_field_name time
add_tag_field true
tag_field_name tag
</match>
Regarding he port number of the aggregator host above, the default is 24224. Note that both TCP packets (event stream) and UDP packets (heartbeat message) are sent to this port, which mean you need to open both TCP and UDP for this port if you have access controls between forwarders and aggregator. Please see the forward Output plugin article to understand more about forward plugin.
Finally, run fluentd with specifiying fluent.conf that you configurea above.
$ fluentd -c ./fluent.conf -vv &
Setup: Fluentd Forwarders
First, to set up Fluentd, run the following command to setup Fluentd. Again If you are not using Ruby Gem for the installation, please refer to the installation document.
# install fluentd
$ sudo gem install fluentd --no-ri --no-rdoc`
# create fluent.conf
$ fluentd --setup
Then, give Fluentd a read access to servers’log files.
$ sudo chmod og+rx /var/log/apache2
$ sudo chmod og+r /var/log/apache2/*
Next, configure fluent.conf, a fluentd configuration file as follows to tail apache access logs and forard event to aggregator
# Apache Access Logs
<source>
@type tail
path /var/log/apache2/access.log # monitoring file
pos_file /tmp/fluentd_pos_file # position file
format apache # format
tag apache.access # tag
</source>
# Forward data to the aggregator
<match apache.access>
@type forward
buffer_type memory
buffer_chunk_limit 8m
buffer_queue_limit 64
flush_interval 1s
<server>
host <Aggregator's hostname or IP>
port 24224
</server>
<secondary>
@type file
path /var/log/fluentd/forward-failed
</secondary>
</match>
Finally, start Fluentd with the configuration above to start log collections
$ fluentd -c ./fluent.conf -vv &
TEST
Let’s check if logs will be forwarded from apache nodes to aggegator and ultimately stored in documentdb. First, create log events by sending test requests to web servers somehow (here using apache bench for example)
$ ab -n 5 -c 2 http://<targetserver>/foo/bar/test.html
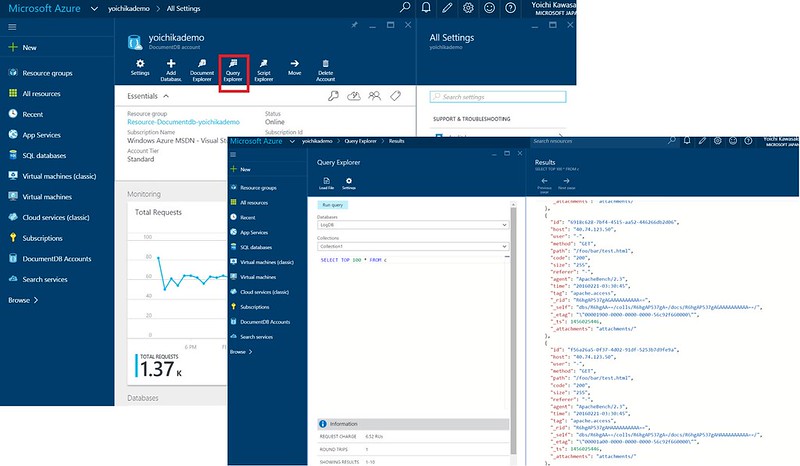
If logs are collected successfully, you can see the logs stored in DocumentDB easily by using Document DB’s query explorer. Go to Azure Portal > Display your DocumentDB dashboard > Query Explorer.
More log collections from external sources
Fluentd’s Input plugins extend Fluentd to retrieve and pull event logs from external sources. An input plugin typically creates a thread socket and a listen socket. It can also periodically pull data from data sources. For examples, listening syslog events, tailing apache/nginx logs, and pulling data from well-known RDBMS/NoSQLs on-premices or on public cloud. See http://www.fluentd.org/plugins
Setup for Advanced senarios
- Using Secure-forward instead of simple forward plugin in order to have communication over SSL between forward servers and aggregator: https://github.com/tagomoris/fluent-plugin-secure-forward
- Configuring DocumentDB’s Hadoop connector that allows DocumentDB to act as both a source and sink for Hive, Pig and MapReduce jobs: https://azure.microsoft.com/en-us/documentation/articles/documentdb-run-hadoop-with-hdinsight/
- Setup Azure Data factory to from DocumentDB to Azure Blob Storage for Archiving the data: https://azure.microsoft.com/en-us/documentation/articles/data-factory-azure-documentdb-connector/
- Configuring DocumentDB’s PowerBI connector that allows DocumentDB to act as a source for PowerBI to create insightful visualizations for DocumentDB data: https://azure.microsoft.com/en-us/blog/unleashing-insights-from-data-in-documentdb-with-power-bi/
Happy log collections with Azure DocumentDB and fluentd!!
END