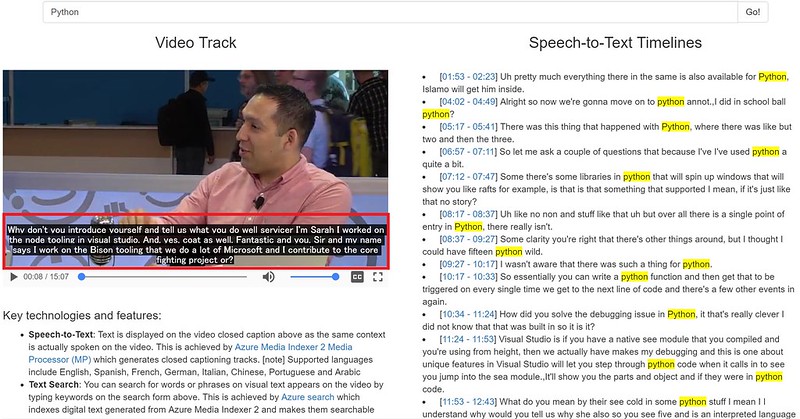
ビデオコンテンツを音声認識エンジンでテキスト化してそれを元にスピーチ検索するデモコンテンツを紹介したい。これは過去にde:code2016というマイクロソフトの開発者向けイベントで行ったブレイクアウトセッション「DEV-18: Azure Search Deep Dive」にて紹介したビデオコンテンツのスピーチ検索デモを簡略化して再利用しやすいものにしたものである。
主要テクノロジーと機能
Azure Media Indexer 2 Previewによる音声からテキスト抽出
このデモではAzure Media Indexer 2 Preview メディア プロセッサー (MP)を使用してビデオコンテンツからテキストを抽出している。このAzure Media Indexer 2 Previewは自然言語処理(NLP)や音声認識エンジンを駆使してビデオコンテンツより字幕用データ(時間やテキスト)や検索可能にするためのメタデータを抽出することができる。Indexer 2という名前の通り前のバージョンであるAzure Media Indexerが存在するが、これと比較すると、Azure Media Indexer 2 Previewは、インデックス作成が高速化され、より多くの言語をサポートしていることが特徴である。2016年11月6日時点で英語、スペイン語、フランス語、ドイツ語、イタリア語、中国語、ポルトガル語、アラビア語などがサポートされている(残念ながら日本語はまだ未サポート)。
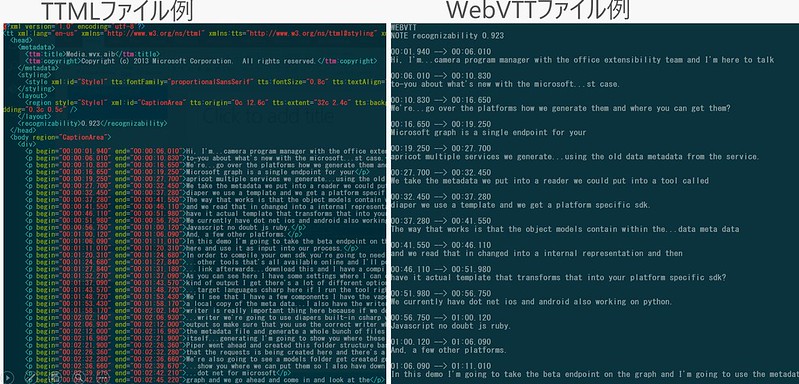
下イメージはAzure Media Indexer 2 (Preview)で生成されるTTMLとWebVTTという代表的な字幕データフォーマット。
HTML5と字幕(Closed Caption)
HTML5にはtrackタグエレメントを使ってビデオファイルに字幕を表示する機能が標準的に実装されている。本デモではHTML5に下記のように動画(Python_and_node.js_on_Visual_Studio.mp4)をVideoソースとしてtrackエレメントに字幕WebVttファイル(build2016breakout.vtt)を指定している。
<video id="Video1" controls autoplay width="600">
<source src="Python_and_node.js_on_Visual_Studio.mp4" srclang="en" type="video/mp4">
<track id="trackJA" src="build2016breakout.vtt" kind="captions" srclang="ja" label="Closed Captions" default>
</video>
Azure Searchによる全文検索
デモページ上部にある検索窓にキーワードを入力してGoボタンを押すとビデオコンテンツの字幕データを全文検索してキーワードにマッチしたテキストとその表示時間に絞り込むことができる。ここでは全文検索エンジンにAzure Searchを使用し、Azure Media Indexer 2 (Preview)より抽出された字幕データを解析して字幕表示時間とその対応テキストを1ドキュメントレコードとしてAzure Searchにインジェストしてその生成されたインデックスに対してキーワードを元に全文検索することで実現している。字幕データ検索用のインデックススキーマは次のように字幕表示時間とその対応テキストをレコード単位となるように定義している。
{
"name": "stt",
"fields": [
{ "name":"id", "type":"Edm.String", "key": true, "searchable": false, "filterable":false, "facetable":false },
{ "name":"contentid", "type":"Edm.String","searchable": false, "filterable":true, "facetable":false },
{ "name":"beginsec", "type":"Edm.Int32", "searchable": false, "filterable":false, "sortable":true, "facetable":false },
{ "name":"begin", "type":"Edm.String", "searchable": false, "filterable":false, "sortable":false, "facetable":false },
{ "name":"end", "type":"Edm.String", "searchable": false, "filterable":false, "sortable":false, "facetable":false },
{ "name":"caption", "type":"Edm.String", "searchable": true, "filterable":false, "sortable":false, "facetable":false, "analyzer":"en.microsoft" }
]
}
デモデータ作成手順
GithubプロジェクトページVideo-STT-Search-Pythonの1. Preparationと2. Batch executionを実施いただければ字幕データ*.vttファイルが生成され、そのテキストがAzure Searchに格納されてデモページ表示のための準備は完了する。最後に表示用のページを生成すれば完了。本デモの表示用ページデータはこちらで、基本的にindex.htmlとsearch.jsの変更のみでいけるはず。
本デモコンテンツについて何か問題を発見した場合はこちらのGithub IssueページにIssueとして登録いただけると幸いである。
Enjoy Video Speech-to-text demo!