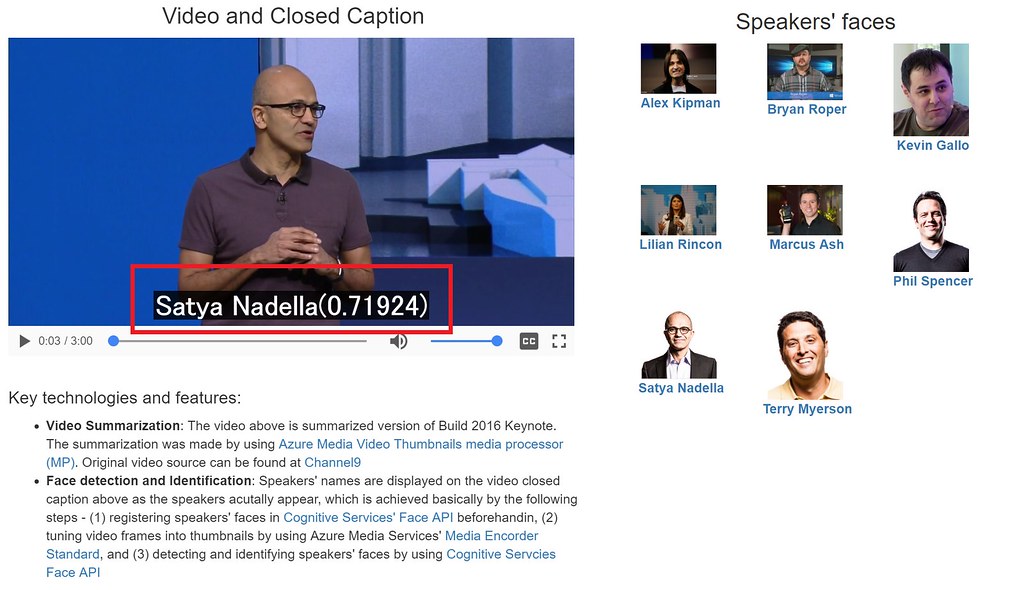
過去に本ブログでビデオコンテンツを切り口とした音声認識やOCR技術を利用したデモを紹介したが、ここではビデオコンテンツの中の人物出現箇所に連動して人物名を字幕で表示させるデモとその実装方法を紹介したい。人物識別にはAzureのCognitive ServicesのFace APIを使っていて、これで動画の中に出現する顔の検出を行い、予め登録している人物リストとのマッチングにより実現している。 Cognitive Serivcesとは視覚、音声、言語、知識などマイクロソフトがこれまで研究を通じて開発してきたさまざまな要素技術をAPIとして提供しているサービスのことで、最近巷で人工知能(AI)だとかインテリジェンスとかいうキーワードをよく耳にするのではないかと思うがAzure利用シナリオでそういったインテリジェンス(知能/知性)を兼ね備えたアプリを作る場合は間違いなく中核となるサービスの1つである。Face APIはその中でも顔の検出・識別や、顔にまつわる感情、特徴などメタデータ抽出に特化したAPIである。
主要テクノロジーと機能
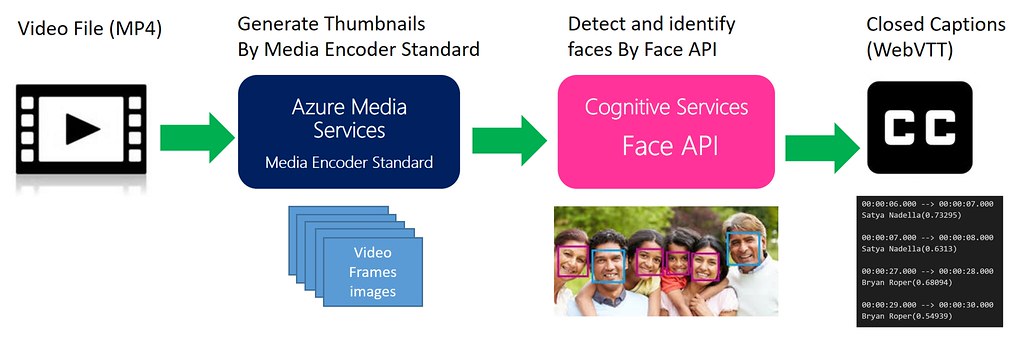
下図は今回のデモ作成のために行っている処理フローと主要テクノロジーを表している。やっていることは大きく分けて3つ: (1) 動画コンテンツをAzure Media Encoder Standardを使ってフレームごとの静止画像の作成, (2) Cognitive ServicesのFace APIを使って1より得られた静止画像から顔の検出を行い予め登録している人物リストとマッチング(最も類似度が高いものを本人とみなす)して人物を識別, (3) 2で得られた各フレーム中の人物情報を時間順に並べて字幕(Closed Caption)用のデータファイルを生成。以下、各処理の詳細について説明する。
1. Azure Media Encoder Standardでフレームごとの静止画生成
残念ながらFace APIはビデオコンテンツから直接顔検出することができないため、一旦ビデオコンテンツから各フレームごとの静止画を生成してその静止画を対象に処理を行う必要がある。ここでは各フレームごとの静止画生成にAzure Media Encoder Standard(MES)を利用する。MESを使うことでエンコードタスクとしてビデオコンテンツに対して様々な処理を行うことができるのだが、MESにはそのエンコードタスクの1つとしてサムネイル生成のためのタスクが用意されており、今回はこのサムネール生成タスクを利用する。他のエンコードタスク同様にサムネイル生成タスクについてもプリセットと呼ばれるエンコードに必要な情報を記述した XML または JSON形式ファイルを用意する必要がある。今回は1秒フレームごとにJPEG形式の静止画(サムネイル)を生成するために次のようなプリセット(amsmp-thumbnail-config.json)を用意した。
{
"Version": 1.0,
"Codecs": [
{
"Start": "00:00:00",
"Step": "00:00:01",
"Type": "JpgImage",
"JpgLayers": [
{
"Quality": 90,
"Type": "JpgLayer",
"Width": 640,
"Height": 360
}
]
}
],
"Outputs": [
{
"FileName": "{Basename}_{Index}{Extension}",
"Format": {
"Type": "JpgFormat"
}
}
]
}
MESによるサムネイル処理実行方法やプリセットの詳細については「Media Encoder Standard を使用した高度なエンコード」や同ページの「サムネイルを生成する」項を参照ください。尚、今回のサムネイル生成のためのエンコーディング処理は小生自作の「azure-media-processor-java」を利用してバッチ実行している。
2. Cognitive Services Face APIによる顔の検出と人物の識別
ここではCognitive ServicesのFace APIを使って1で得られたフレームごとの静止画像に対して顔検出を行い、予め登録している人物リスト(Face APIでいうところのPerson Group)と比較して最も類似度の高い人物(Face APIでいうところのPerson )をその本人として識別する。
2-1. 人物リスト(Person Group)の作成
人物リスト(Person Group)の作成で必要な作業とFace APIの利用インターフェースは次の通り:
- Create a Person Group APIを使って Person Groupを作成
- 上記で作成したPerson Groupの中にCreate a Person APIで人物ごとにPersonを作成する。作成されたPerson対してAdd a Person Face APIでその人物の顔画像を登録する。Face APIでは各Personに最大248枚の顔画像を登録が可能となっており、さまざまな種類の顔を登録することで機械学習によりその人物の顔識別の精度が向上するとされている。
- 上記でPerson Groupに対して登録されたPersonデータ(Personごとの顔データ)は最終的にTrain Person Group APIでトレーニングされることで、次の2-2で行う顔識別(Face Identify API)処理で利用可能なデータとなる。注意点として、いくらある人物の顔画像を登録したとしてもそれがトレーニングされない限り顔識別処理において有効にはならないため、新しく顔を登録した場合はトレーニング処理を忘れずに行ってください(この手のことは自動化しておいてください)。
2-2. 静止画像中の顔認識と人物識別
ここで行う処理の流れとFace APIの利用インターフェースは次の通り:
- Face Detect APIを使って静止画像中の顔を検出する。検出された顔ごとに固有のIDが得られる。尚、1枚の画像で複数の顔が検出された場合、最大64までは取得可能となっている(2016年12月現在)。
- 上記の顔検出で得られた顔IDを元にFace Identify APIを使って2-1で登録した人物リスト(Person Group)に対して人物検索を行い顔の類似度(0~1の数値)が高いもの順に一覧を取得することができる。ここでは最も類似度が高い人物をその顔の人物として決定する。
3. 字幕(Closed Caption)データファイルの生成
2で得られた各フレーム中の人物情報と各フレームの時間を元に字幕用のデータフォーマットであるWebVTTフォーマットファイルを生成する。以下、6秒~30秒までの字幕出力を期したWebVTTファイルのサンプルであるが、見ていただいてわかる通りフレームの時間(最小秒単位)とそこで得られた人物名をセットで記述するとても単純なフォーマットとなっている。
00:00:06.000 --> 00:00:07.000
Satya Nadella(0.73295)`
00:00:07.000 --> 00:00:08.000
Satya Nadella(0.6313)
00:00:27.000 --> 00:00:28.000
Bryan Roper(0.68094)
00:00:29.000 --> 00:00:30.000
Bryan Roper(0.54939)
各フレームの時間について、今回のビデオコンテンツのフレームは1秒ごとに取得しており、フレームごとの静止画像ファイルにはフレームの順番がPostfixとしてファイル名に含まれているため単純にファイル名からフレームの時間が特定できるようになっている(例, 10番目のファイル= videoassetname_000010.jpg)。もし今回のような機械的なルールがない場合はフレーム用画像ファイル名と時間のマッピングが必要となる。
ビデオコンテンツと字幕の再生は「ビデオコンテンツの音声認識デモ」でも紹介したようにHTML5のtrackタグエレメントによるビデオファイルの字幕表示機能使って人物名の字幕表示を実現している。本デモではHTML5に下記のようにビデオファイル(MP4)をVideoソースとしてtrackエレメントにWebVTTファイル(build2016keynote.vtt)を指定している。
<video id="Video1" controls autoplay width="600">
<source src="KEY01_VideoThumbnail.mp4" srclang="en" type="video/mp4">
<track id="trackJA" src="build2016keynote.vtt" kind="captions" srclang="ja" label="Person Name" default>
</video>
デモデータ作成手順
GithubプロジェクトページVideoFramesFaceRecognition-Pythonの1. Preparationと2. Batch executionを実施いただければFace APIで識別した各フレームごとの人物名を元に字幕データ*.vttファイルが生成されデモページ表示のための準備は完了する。最後に表示用の静的ページを生成すれば完了。本デモの表示用ページデータはこちらで、基本的にindex.htmlの変更のみでいけるはず。
本デモコンテンツについて何か問題を発見した場合はこちらのGithub IssueページにIssueとして登録いただけると幸いである。
Azure Media Analytics Face Detectorを活用した処理の効率化
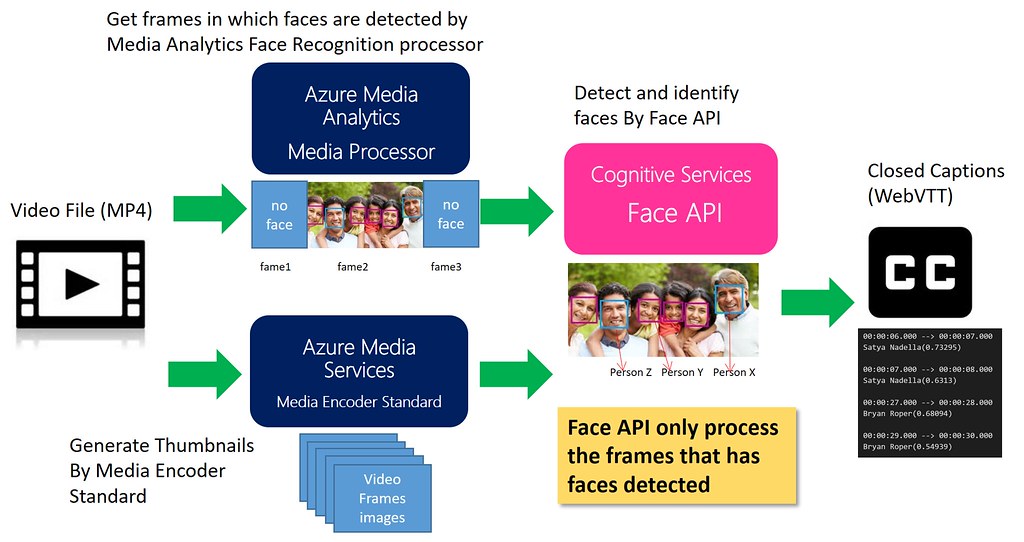
今回の人物識別ではビデオコンテンツの全てのフレームに対してFace APIを使って顔検出処理を行っているが、これでは顔出現フレームが少ないコンテンツの場合には無駄なFace APIリクエストが大量に発生してしまうため効率的な処理とは言えない。ということで、ここではAzure Media Face Detectorを活用して処理を効率化する方法を紹介したい。
Azure Media Face DetectorはAzure Media Servicesのメディアプロセッサ(MP)の1つで、ビデオコンテンツから顔の検出や感情の検出をすることができる。残念ながらAzure Media Face DetectorはFace APIのように顔の識別を行うことはできないものの、ビデオコンテンツから直接顔を検出することができる、即ちビデオコンテンツから直接顔が存在するフレームを特定することができる。よって、この機能を利用して一旦Azure Media Face Detectorで顔が検出されたフレームのみに絞り込んでからFace APIを使ってフレームの静止画像に対して顔検出・顔識別を行うことで無駄なFace APIリクエストを減らして処理の効率化を図ることができる。処理フローとしては次のようなイメージ。
おまけ: Video Summarization
デモページをみていただくとお分かりのように今回のデモでは3分のビデオコンテンツを題材としているが、元ネタはChannel9で公開されている計138分のBuild 2016のキーノートセッションである。このキーノートのセッションはデモコンテンツとしてはあまりに長かったのでこれをAzure Media Video Thumbnailsメディアプロセッサ(MP)を使って3分に要約している。Azure Media Video Thumbnailsはアルゴリズムベースで特徴シーンの検出とそれらを結合(サブクリップ)してビデオコンテンツを指定した長さに要約することができるMPで、現在Public Previewリリース中(2016年12月現在)。
参考までに、要約(3分:180秒)に使用したAzure Media Video Thumbnailsのタスクプリセットは以下の通り:
{
"version": "1.0",
"options": {
"outputAudio": "true",
"maxMotionThumbnailDurationInSecs": "180",
"fadeInFadeOut": "true"
}
}
END