Azure Searchのインデックス更新方法には大きく分けてPUSHとPULLの2種類ある。PUSHは直接Indexing APIを使ってAzure SearchにコンテンツをPOSTして更新。PULLは特定データソースに対してポーリングして更新で、Azure Searchの場合、DocumentDBとSQL Databaseの2種類のデータソースを対象にワンタイムもしくは定期的なスケジュール実行が可能となっている。ここではDocumentDBをデータソースとしてインデックスを更新する方法を紹介する。
サンプル構成と処理フローの説明
データソースにDocumentDBを利用する。データ「DOCUMENTDB PYTHON SDKとFEEDPARSERで作る簡易クローラー」においてクローリングされDocumentDBに保存されたブログ記事データを使用する。そしてDocumentDBを定期的にポーリングを行い更新があったレコードのみをAzure Searchインデックスに反映するためにDocumentDBインデクサーを設定する。全体構成としては下記の通りとなる。

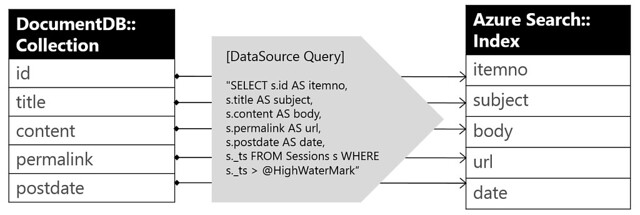
DocumentDBと更新先検索インデックスのフィールドのマッピング
DocumentDBをデータソースとしてAzure Searchインデックスに更新を行うためDocumentDBの参照先コレクションのフィールドと更新先Azure Searchインデックスのフィールドをマッピングを行う。マッピングはデータソース定義中のDocumentDB参照用Queryで行う。Azure SearchインデックスにインジェストするフィールドをDocumentDBのSELECTクエリー指定するのだが、Azure SearchとDocumentDBのフィールドが異なる場合は下図のようにSELECT “Docdbフィールド名” AS “Searchフィールド名"でインジェスト先フィールド名を指定する。データソース定義については後述の設定内容を確認ください。
Configuration
以下1~4のステップでデータソースの作成、検索インデックスの作成、インデクサーの作成、インデクサーの実行を行う。
(1) データソースの作成
credential.connectionStringで接続先DocumentDB文字列と対象データベースの指定を行う。container.(name|query)で対象コレクション名と参照用SELECT文を指定する。SELECT文はDocumentDBとインジェスト先Azure Searchのフィールドセット(フィールド名と数)が同じであれば省略可。詳細はこちらを参照。
#!/bin/sh
SERVICE_NAME='<Azure Search Service Name>'
API_VER='2015-02-28-Preview'
ADMIN_KEY='<API KEY>'
CONTENT_TYPE='application/json'
URL="https://$SERVICE_NAME.search.windows.net/datasources?api-version=$API_VER"
curl -s\
-H "Content-Type: $CONTENT_TYPE"\
-H "api-key: $ADMIN_KEY"\
-XPOST $URL -d'{
"name": "docdbds-article",
"type": "documentdb",
"credentials": {
"connectionString": "AccountEndpoint=https://<DOCUMENTDB_ACCOUNT>.documents.azure.com;AccountKey=<DOCUMENTDB_MASTER_KEY_STRING>;Database=<DOCUMENTDB_DBNAME>"
},
"container": {
"name": "article_collection",
"query": "SELECT s.id AS itemno, s.title AS subject, s.content AS body, s.permalink AS url, s.postdate AS date, s._ts FROM Sessions s WHERE s._ts > @HighWaterMark"
},
"dataChangeDetectionPolicy": {
"@odata.type": "#Microsoft.Azure.Search.HighWaterMarkChangeDetectionPolicy",
"highWaterMarkColumnName": "_ts"
},
"dataDeletionDetectionPolicy": {
"@odata.type": "#Microsoft.Azure.Search.SoftDeleteColumnDeletionDetectionPolicy",
"softDeleteColumnName": "isDeleted",
"softDeleteMarkerValue": "true"
}
}'
(2) インデックスの作成
下記のスキーマでAzure Searchインデックスを作成する。
{
"name": "articles-test",
"fields": [
{ "name":"itemno", "type":"Edm.String", "key": true, "searchable": false },
{ "name":"subject", "type":"Edm.String", "filterable":false, "sortable":false, "facetable":false},
{ "name":"body", "type":"Edm.String","filterable":false,"sortable":false, "facetable":false, "analyzer":"ja.lucene"},
{ "name":"url", "type":"Edm.String", "sortable":false, "facetable":false },
{ "name":"date", "type":"Edm.DateTimeOffset", "facetable":false}
]
}
(3) DocumentDBインデクサーの作成
DocumentDBインデクサー作成のための設定。DatSourceNameとtargetIndexNameにそれぞれ1で作成したデータソース名とインジェスト先のインデックス名を指定する。スケジュール実行させたい場合は下記の通りscheduleを設定する。ここではintervalをPT5Mとしているがこれは5分毎実行を意味する。詳しくはこちらを参照。
#!/bin/sh
SERVICE_NAME='<Azure Search Service Name>'
API_VER='2015-02-28-Preview'
ADMIN_KEY='<API KEY>'
CONTENT_TYPE='application/json'
URL="https://$SERVICE_NAME.search.windows.net/indexers?api-version=$API_VER"
curl -s\
-H "Content-Type: $CONTENT_TYPE"\
-H "api-key: $ADMIN_KEY"\
-XPOST $URL -d'{
"name": "docdbindexer",
"dataSourceName": "docdbds-article",
"targetIndexName" : "articles",
"schedule":
{
"interval" : "PT5M",
"startTime" :"2015-06-17T00:00:00Z"
}
}'
(4) インデクサーの明示的に実行
スケジュール実行ではなくインデクサーをすぐに実行したい場合は下記のフォーマットでPOSTリクエストを送信する。
POST https://[Search service name].search.windows.net/indexers/[indexer name]/run?api-version=[api-version]
api-key: [Search service admin key]
実行結果確認方法
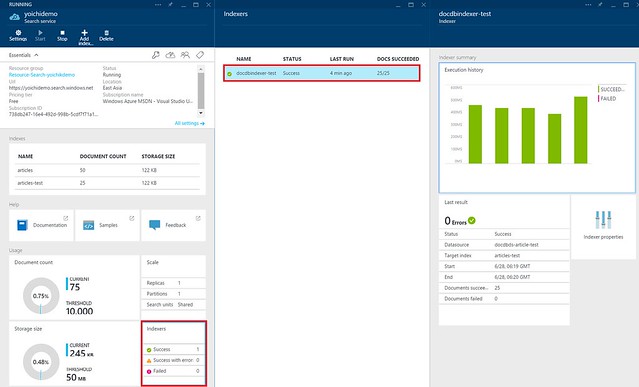
上記イメージの通りAzureポータル(preview)よりAzure Search → indexersタイルをたどることでインデクサーの実行結果や過去の履歴を確認することができる。ただし、ここではAPI経由で取得する方法を紹介する。
下記フォーマットでGETリクエストすることでインデクサーの現在の稼働状態と実行履歴を取得することができる。実行履歴は最後の実行結果だけではなく最近完了した50件の実行内容が含まれる。
GET https://[Search service name].search.windows.net/indexers/[indexer name]/status?api-version=[api-version]
api-key: [Search service admin key]
以下実行結果。executionHistoryが履歴、lastResultが最後の実行結果、statusが現在のインデクサーのステータスとなっている。
{
"@odata.context": "https://yoichidemo.search.windows.net/$metadata#Microsoft.Azure.Search.V2015_02_28_Preview.IndexerExecutionInfo",
"executionHistory": [
{
"endTime": "2015-06-25T05:55:01.393Z",
"errorMessage": "Data source 'docdbds-article' does not exist",
"errors": [],
"finalTrackingState": null,
"initialTrackingState": null,
"itemsFailed": 0,
"itemsProcessed": 0,
"startTime": "2015-06-25T05:55:01.393Z",
"status": "transientFailure"
},
...(omit)...
{
"endTime": "2015-06-25T02:15:02.155Z",
"errorMessage": null,
"errors": [],
"finalTrackingState": "1434871500",
"initialTrackingState": "1434871500",
"itemsFailed": 0,
"itemsProcessed": 0,
"startTime": "2015-06-25T02:15:01.452Z",
"status": "success"
},
{
"endTime": "2015-06-25T02:10:01.144Z",
"errorMessage": null,
"errors": [],
"finalTrackingState": "1434871500",
"initialTrackingState": "1434871500",
"itemsFailed": 0,
"itemsProcessed": 0,
"startTime": "2015-06-25T02:10:00.022Z",
"status": "success"
}
],
"lastResult": {
"endTime": "2015-06-25T05:59:02.016Z",
"errorMessage": "Data source 'docdbds-article' does not exist",
"errors": [],
"finalTrackingState": null,
"initialTrackingState": null,
"itemsFailed": 0,
"itemsProcessed": 0,
"startTime": "2015-06-25T05:59:02.016Z",
"status": "transientFailure"
},
"name": "docdbindexer",
"status": "running"
}
Content DBの有効性について
ここではAzure SearchのfeedingソリューションとしてDocumentDBを使用したPULLインデックス更新方法を紹介した。このようにクローリングされたデータを直接Azure SearchのIndex APIを使ってインデックスを更新するのではなく、今回のDocumentDBのように所謂Content DBに格納してからそれを元にインデックスを更新するのにはいくつか意味がある。例えば、インデックス構造を変更したい場合、再フィードが必要になるがContent DBがあれば再度クローリングする必要がない。通常クローリング(特にフルクローリング)のコストは大きい。また、Content DBがあれば別アカウント、リージョンにインデックスのレプリカの構築、他に、同一のデータを使って別構造のインデックを構築するといったことも容易に可能になる。
さらに、現時点でAzure Searchがデータ加工のためのパイプラインの仕組み(Lucene/Solr, ElasticSearchでいうところのカスタムAnalyzer)がないことから、インデックスに放り込む前の一時データ加工用のデータベースとしても有効であると考えている。