OCRとはOptical Character Recognitionの略で日本語にすると光学文字認識と訳されており、ざっくりと画像の中の文字をテキストに変換する技術のことを指す。テキストに変換されるということは勘が鋭い皆さんはお気づきだと思うが、テキストの全文検索であったり、テキストから音声への変換、さらには機械翻訳を使って多言語への変換といった展開が考えられる。そんな可能性を秘めたOCRであるが、ここではそのOCRの技術を使ってビデオファイルから抽出したテキストデータを元にビデオに字幕表示したり、動画中に表示される文字を全文検索をするデモを紹介したい。内容的には「Azure Media & Cognitiveデモ:Speech-To-Text」で紹介したデモのOCR版といったところ。
主要テクノロジーと機能
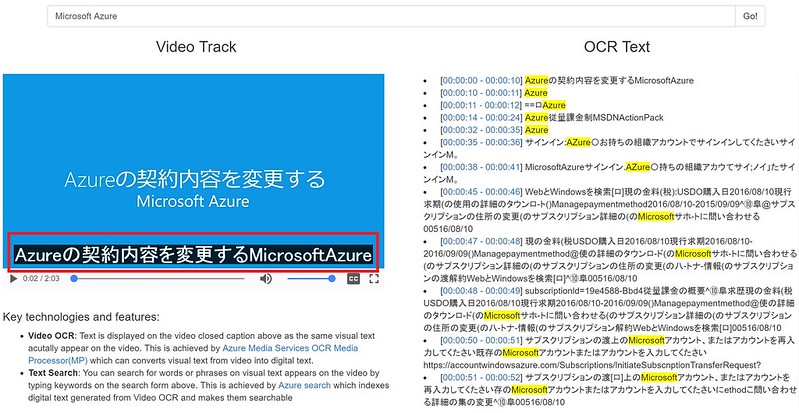
Azure Media OCRメディアプロセッサによるテキスト抽出
このデモではAzure Media OCRメディアプロセッサー(MP)を使用してビデオファイル内のテキストコンテンツを検出してテキストファイルを生成している。OCRメディアプロセッサーは入力パラメータによりビデオ解析の挙動を調整することができる。主なパラメータとしては検索対象テキストの言語(日本語もサポート)、テキストの向き、サンプリングレート、ビデオフレーム内のテキスト検出対象のリージョンがあるが、本デモでの入力パラメータ(Video-OCR-Search-Python/src/ocr-detectregion.json)は以下の通り検索対象言語は日本語、1秒おきのサンプリングレート、テキスト検出対象のリージョンからビデオフレーム内の上部1/4を省く設定(検出対象をフレームトップから85 pixel以下を対象)にしている。
{
"Version":"1.0",
"Options":
{
"Language":"Japanese",
"TimeInterval":"00:00:01.000",
"DetectRegions":
[
{"Left":"0","Top":"85","Width":"1280","Height":"635"}
]
}
}
そして、Azure Media OCRメディアプロセッサはビデオで検出された文字を下記のような表示時間に基づいてセグメント化された形で結果出力する。結果ファイルの完全版はこちら(azuresubs.json)を参照ください。
{
"fragments": [
{
"start": 0
"interval": 319319,
"duration": 319319,
"events": [
[
{
"language": "Japanese",
"text": "Azure の 契 約 内 容 を 変 更 す る Microsoft Azure"
}
]
]
},
{ /* fragment1 */ },
{ /* fragment2 */ },
...
{ /* fragmentN */ }
],
"version": 1,
"framerate": 29.97,
"height": 720,
"width": 1280,
"offset": 0,
"timescale": 30000
}
入力パラメータと出力形式共に詳細はこちらのドキュメントを参照いただくとしてAzure Media OCRメディアプロセッサ利用の注意点として次の2つがある:
- 「Azure Media OCR Simplified Output」の記事でアナウンスされている通り2016年9月ごろからデフォルトの出力形式が上記ドキュメントページにある詳細形式からシンプル形式に変わっている
- Azure Media OCRメディアプロセッサー(MP)は現時点(2016年11月7日)では正式リリースではなくプレビューリリース
字幕(Closed Caption)データフォーマットへの変換
まず上記Azure Media OCRメディアプロセッサー(MP)から出力されたJSONファイルの内容を元に字幕用のデータフォーマットであるWebVTTフォーマットファイルを生成している。そして「Azure Media & Cognitiveデモ:Speech-To-Text」でも紹介したようにHTML5のtrackタグエレメントによるビデオファイルの字幕表示機能使ってOCRの内容の字幕表示を実現している。本デモではHTML5に下記のように動画(TransferanAzuresubscriptionJP.mp4)をVideoソースとしてtrackエレメントにWebVTTファイル(azuresubs.vtt)を指定している。
<video id="Video1" controls autoplay width="600">
<source src="TransferanAzuresubscriptionJP.mp4" srclang="en" type="video/mp4">
<track id="trackJA" src="azuresubs.vtt" kind="captions" srclang="ja" label="OCR Subtitle" default>
</video>
Azure Searchによる全文検索
デモページ上部にある検索窓にキーワードを入力してGoボタンを押すとビデオコンテンツからOCR抽出されたテキストを元に生成された字幕データを全文検索してキーワードにマッチしたテキストとその表示時間に絞り込むことができる。仕組みは「Azure Media & Cognitiveデモ:Speech-To-Text」と全く同じで、Azure Searchを使用して字幕データを解析して字幕表示時間とその対応テキストを1ドキュメントレコードとしてAzure Searchにインジェストしてその生成されたインデックスに対してキーワードを元に全文検索することで実現している。検索用のインデックススキーマもまったくおなじで次のように字幕表示時間とその対応テキストをレコード単位となるように定義している。
{
"name": "ocr",
"fields": [
{ "name":"id", "type":"Edm.String", "key": true, "searchable": false, "filterable":false, "facetable":false },
{ "name":"contentid", "type":"Edm.String","searchable": false, "filterable":true, "facetable":false },
{ "name":"beginsec", "type":"Edm.Int32", "searchable": false, "filterable":false, "sortable":true, "facetable":false },
{ "name":"begin", "type":"Edm.String", "searchable": false, "filterable":false, "sortable":false, "facetable":false },
{ "name":"end", "type":"Edm.String", "searchable": false, "filterable":false, "sortable":false, "facetable":false },
{ "name":"caption", "type":"Edm.String", "searchable": true, "filterable":false, "sortable":false, "facetable":false, "analyzer":"ja.microsoft" }
]
}
デモデータ作成手順
GithubプロジェクトページVideo-OCR-Search-Pythonの1. Preparationと2. Batch executionを実施いただければOCR抽出されたテキストを元に字幕データ*.vttファイルが生成され、そのテキストがAzure Searchに格納されてデモページ表示のための準備は完了する。最後に表示用のページを生成すれば完了。本デモの表示用ページデータはこちらで、基本的にindex.htmlとsearch.jsの変更のみでいけるはず。
本デモコンテンツについて何か問題を発見した場合はこちらのGithub IssueページにIssueとして登録いただけると幸いである。
Enjoy Video OCR demo!